记一次成功的 Btrfs RAID 1 掉盘救回
很不幸,我也不希望新年的时候在修自己的伺服器,但是它的 Btrfs 确实是坏了
发现故障
这台伺服器的一部分功能是用来做自己 pt 的种,有一天我想下一点种的时候发现怎么样都没法把种传上去, qb web 是正常的,但这是为什么呢?
上去看了一眼 journalctl 发现一堆红色的 btrfs 报错。
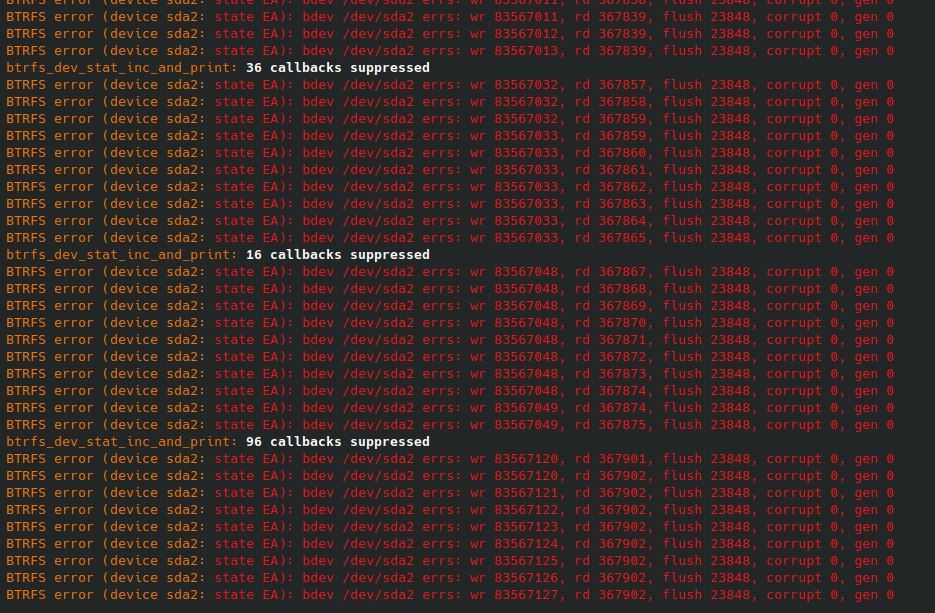
初步看了一下,大概是某个盘掉了。不过还好,我这个盘是 raid 1 由 btrfs 挂载,数据应该没有问题。
盘的话,因为是 Hetzner 的杜甫,所以请他们帮忙换个盘就行。
换盘
发工单请 Hetzner 那边帮忙换一个能用的磁盘即可。它有两个选项,一个是保证磁盘 < 1000h 的使用时间,不过要额外加钱,另一个是尽量新,不需要额外的钱。那这样我们选尽量新就行(虽然给了我们一个 10000+ h 的)。
接着它要我们填写受影响的磁盘序列号,我这里只有两块磁盘,盘都没有了怎么读序列号,于是我们就填写了没有受影响的磁盘序列号。它也可以选择时间进行替换,还有替换的方式。因为跑的是非关键服务,就让它 ASAP 吧,同时也可以关机替换,反正无所谓。
接着等 Hetzner 给我们发邮件就可以了。
修复 btrfs
大概过了一个小时, Hetzner 发送邮件给我大概说他们已经替换完成了,现在服务器已经帮我们重新打开应该可以正常使用了。在发工单之前,我已经通过控制台让服务器先进入救援模式,这样它就不会尝试启动系统,而进入到网络挂载的系统中。
引导救援系统成功之后,首先先检查一下目前磁盘的状态。 fdisk -l 可以看到两块磁盘都已经可以重新读出来了,一块是我们以前使用过的所以上面存在分区表。
首先先把新的磁盘分区一下,分成目前磁盘的分区格式,这里就不再概述了。
然后检查一下 btrfs 分区的状态
# btrfs fi show
Label: 'arch' uuid: 00000000-0000-0000-0000-000000000000
Total devices 2 FS bytes used 5.16TiB
devid 1 size 0 used 0 path MISSING
devid 2 size 5.44TiB used 5.43TiB path /dev/sda2
可以看到它并不能读到另一个盘,这时候我们直接使用 replace 大法,从原有的 raid 1 数据盘中替换成另一个盘。
# btrfs replace start 1 /dev/sdb2 /mnt
这里要注意一个点,就是你替换的 device id 一定是你 MISSING 的,而不是现有的 device id ,不要问我为什么这样提醒。
然后经过漫长的等待之后, replace 操作就顺利完成了。
# btrfs fi show
Label: 'arch' uuid: e753ab70-b8ad-4983-9a87-eb19c53cb93f
Total devices 2 FS bytes used 5.16TiB
devid 1 size 5.44TiB used 5.43TiB path /dev/sda2
devid 2 size 5.44TiB used 5.44TiB path /dev/sdb2
恢复 btrfs 的 profile
替换完之后还有一些步骤,比如说修复引导,因为引导可能是之前已经损坏的盘上的,这部分就不细述了。
成功引导进系统之后,我发现有一个奇怪的事情,就是我目前的盘上有 raid 1 的配置,也有 single 的配置。
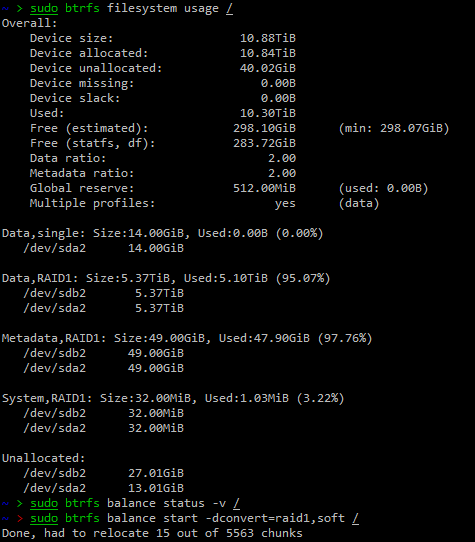
经过我多方搜索,发现只要对 data 部分进行 balance 就行
# btrfs balance start -dconvert=raid1,soft /
这里加 soft 可以直接跳过已经是正确 raid 的部分,从而加快转换的速度。
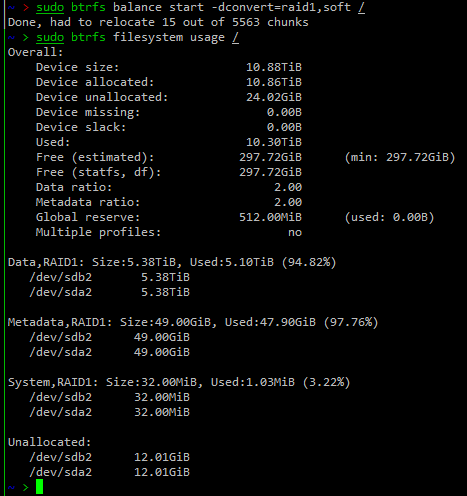
至此, btrfs 的文件系统就恢复完成了。